
- 9 mars 2022
L’anonymisation des données est un concept important à connaitre depuis l’entrée en vigueur du RGPD (GDPR), le Règlement Général sur la Protection des Données. Chaque dirigeant d’entreprise se doit d’exploiter ses données en respectant la vie privée de chacun. Pour cela, l’anonymisation est alors un bon compromis.
Nous allons donc vous expliquer les principes de l’anonymisation des données ainsi que les techniques associées.
QU’EST-CE QUE L’ANONYMISATION DES DONNÉES ET POURQUOI L’UTILISER ?
L’enjeu de l’anonymisation est simple : “rendre impossible l’identification d’une personne à partir d’un jeu de données et permettre, ainsi, de respecter sa vie privée.” (CNIL)
L’anonymisation est un traitement qui consiste à utiliser un ensemble de techniques de manière à rendre impossible toute identification de la personne par n’importe quel moyen et de manière irréversible.
Les raisons d’anonymisation de données sont diverses :
- Exploiter des données personnelles dans le respect des droits et libertés des personnes
- Publier en ligne des informations publiques sans données personnelles (open data)
- Conserver des données au-delà de leur durée de conservation
Clément, Data Scientist chez Cross Data, nous en dit plus sur les bénéfices de l’anonymisation des données :
« Parfois il arrive qu’on crée un projet ou une solution dont on est très fière, qu’on aimerait partager à d’autres personnes ou présenter à d’autres entreprises, cependant on ne peut pas car les données sont confidentielles. En anonymisant nos données et en créant un jeu de données fictif, on peut donc passer outre ces barrières et présenter ce projet qui nous intéresse tant, sans pour autant mettre en danger la confidentialité des données. »
COMMENT ANONYMISER SES DONNÉES EN THÉORIE ?
Pour construire un processus d’anonymisation pertinent, il est conseillé :
- D’identifier les informations à conserver selon leur pertinence (ex : la répartition des prix)
- De supprimer les éléments d’identification directe ainsi que les valeurs rares qui pourraient permettre un ré-identification aisée des personnes (par exemple, la présence de l’âge des individus peut permettre de ré-identifier très facilement les personnes centenaires)
- De distinguer les informations importantes des informations secondaires ou inutiles (c’est-à-dire supprimables, par exemple un libellé quand on a déjà un intitulé)
- De définir la finesse idéale et acceptable pour chaque information conservée
- Randomiser les données en ajoutant un biais est un bon moyen de garder la distribution originale tout en anonymisant les données
- Généraliser des données dont la granularité serait potentiellement trop fine (et donc trop indicative) : par exemple pour une date de naissance du type dd:mm:yyyy hh:ss passer à mm:yyyy
Voici un exemple simple d’anonymisation de noms et de mails :
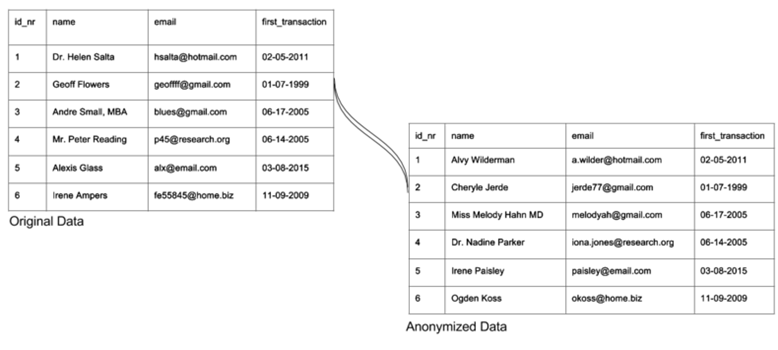
Ici on voit que certaines informations ne sont pas encore anonymisées, on pourrait encore randomiser les id et appliquer un delta sur les dates !
L’ANONYMISATION DE DONNÉES EN PRATIQUE
Anonymisation avec Faker
Faker est une librairie python permettant de générer des données aléatoires. L’avantage est qu’elle permet de générer tout type de données : des noms, des adresses, des numéros, des dates…
Cette librairie est utile pour anonymiser une variable mais nécessiterait davantage de manipulations pour pouvoir anonymiser un jeu de données en entier.
Voici un cas d’usage simple :
# Importation de faker
from faker import Faker
# Définition d'une instance française (il existe pleins de langues différentes)
fake = Faker('fr_FR')
# On peut ensuite générer tout un tas d'information, ici un nom français
fake.name() #retourne par exemple 'Sabine-Michelle Jourdan'
from faker import Faker
faker = Faker()
print(f'Email: {faker.email()}')
print(f'Safe email: {faker.safe_email()}')
print(f'Free email: {faker.free_email()}')
print(f'Company email: {faker.company_email()}')
print('------------------------------------')
print(f'Host name: {faker.hostname()}')
print(f'Domain name: {faker.domain_name()}')
print(f'Domain word: {faker.domain_word()}')
print(f'TLD: {faker.tld()}')
print('------------------------------------')
print(f'IPv4: {faker.ipv4()}')
print(f'IPv6: {faker.ipv6()}')
print(f'MAC address: {faker.mac_address()}')
print('------------------------------------')
print(f'Slug: {faker.slug()}')
print(f'Image URL: {faker.image_url()}')
Email: hescobar@acevedo.info
Safe email: jonesgregory@example.net
Free email: zchambers@yahoo.com
Company email: paulbailey@gordon-woods.com
------------------------------------
Host name: desktop-12.rodriguez-underwood.com
Domain name: henry.com
Domain word: davis
TLD: com
------------------------------------
IPv4: 192.31.48.26
IPv6: 75cd:2c43:37f5:774c:dd:5a2f:ae5d:bfc9
MAC address: 3d:b1:39:ec:c6:53
------------------------------------
Slug: of-street-fight
Image URL: https://placeimg.com/311/871/any
Faker est très utile dans l’anonymisation d’un dataset car cela permet de générer rapidement des faux noms, adresses, numéro de téléphone, référence de produits etc.
Voici quelques références :
Pour aller plus loin, l’ensemble des possibilités est disponible à l’adresse suivante : https://faker.readthedocs.io/en/master/providers.html
Données de synthèse avec SDV
La synthétisation de données peut être comparé à un soda light. Pour être efficace, le soda light doit ressembler au vrai soda : même goût, couleur etc. Cependant, il se différencie par un aspect invisible à l’œil nu : il est allégé en sucre. Dans notre cas, la synthétisation des données a pour but de ressembler aux vraies données : même distribution, mêmes variables, même caractéristique SAUF sur un point : les données sont anonymes et ne permettent pas d’identifier de potentielles informations personnelles.
En pratique sur python
Il existe un package SDV “Synthetic Data Vault”. C’est un écosystème de bibliothèques de génération de données synthétiques qui permet aux utilisateurs d’apprendre facilement des ensembles de données à table unique, multi-tables et séries temporelles pour générer plus tard de nouvelles données synthétiques qui ont le même format et les mêmes propriétés statistiques que l’ensemble de données d’origine.
Il suffit d’instancier un modèle de type CTGAN (GAN-based Deep Learning : https://sdv.dev/SDV/user_guides/single_table/ctgan.html#ctgan). Ce modèle utilise des méthodes de deep learning pour synthétiser les données et reprendre les mêmes caractéristiques du dataset de base.
Voici un exemple d’utilisation :
In [1]: from sdv.demo import load_tabular_demo
#Import d'un dataset à synthétiser
In [2]: data = load_tabular_demo('student_placements')
In [3]: data.head()
Out[3]:
student_id gender second_perc high_perc high_spec degree_perc degree_type work_experience experience_years employability_perc mba_spec mba_perc salary placed start_date end_date duration
0 17264 M 67.00 91.00 Commerce 58.00 Sci&Tech False 0 55.0 Mkt&HR 58.80 27000.0 True 2020-07-23 2020-10-12 3.0
1 17265 M 79.33 78.33 Science 77.48 Sci&Tech True 1 86.5 Mkt&Fin 66.28 20000.0 True 2020-01-11 2020-04-09 3.0
2 17266 M 65.00 68.00 Arts 64.00 Comm&Mgmt False 0 75.0 Mkt&Fin 57.80 25000.0 True 2020-01-26 2020-07-13 6.0
3 17267 M 56.00 52.00 Science 52.00 Sci&Tech False 0 66.0 Mkt&HR 59.43 NaN False NaT NaT NaN
4 17268 M 85.80 73.60 Commerce 73.30 Comm&Mgmt False 0 96.8 Mkt&Fin 55.50 42500.0 True 2020-07-04 2020-09-27 3.0
Ici on voit très clairement qu’il y a des informations sensibles comme des identifiants, des salaires…
On va donc essayer d’imiter ce dataset mais en créant des données de synthèse. On instancie donc un modèle (liste de tous les modèles dispos : https://sdv.dev/SDV/user_guides/single_table/models.html) sur nos données :
In [4]: from sdv.tabular import CTGAN
In [5]: model = CTGAN()
In [6]: model.fit(data)
Puis on génère autant de données qu’on le souhaite !
Le modèle se chargera d’essayer de respecter les différentes caractéristiques du dataset de bases (distributions…).
In [7]: new_data = model.sample(200)
In [8]: new_data.head()
Out[8]:
student_id gender second_perc high_perc high_spec degree_perc degree_type work_experience experience_years employability_perc mba_spec mba_perc salary placed start_date end_date duration
0 17344 F 64.155748 66.241513 Science 68.356744 Comm&Mgmt False 0 55.148030 Mkt&Fin 63.498478 NaN False 2020-03-22 2020-06-09 6.0
1 17452 M 81.467673 69.151198 Commerce 47.264686 Comm&Mgmt False 0 50.833650 Mkt&HR 61.307564 28003.354285 False 2020-03-16 2020-04-17 3.0
2 17472 M 35.897985 62.958254 Commerce 65.403194 Sci&Tech False 0 71.220195 Mkt&HR 50.336099 20729.765728 True 2020-02-23 2020-08-07 12.0
3 17488 M 52.465504 75.102777 Commerce 52.306795 Sci&Tech True 0 70.589755 Mkt&Fin 60.121445 30641.413840 True NaT 2020-11-22 NaN
4 17451 F 38.601610 86.599410 Commerce 59.757815 Comm&Mgmt False 0 46.437669 Mkt&HR 54.741017 44142.609379 True NaT 2020-11-25 NaN
Libre à vous d’ensuite sauvegarder ou partager votre modèle ! La démo complète est disponible ici.
Clément, Data Scientist chez Cross Data, nous en dit plus sur les difficultés pour anonymiser des données :
« La principale difficulté est de réussir à recréer un jeu de données similaire tout en éliminant toute possibilité d’identification des données. Cela nécessite beaucoup de réflexions pour trouver les méthodes adéquates. Il y a également une longue phase de vérification du jeu de données anonymisé pour être sûr qu’il soit conforme aux normes mais qu’il puisse quand même permettre un storytelling intéressant. »
COMMENT VÉRIFIER SI NOS DONNÉES SONT BIEN ANONYMISÉES ?
Selon la CNIL il existe plusieurs moyens de vérifier que nos données sont bien anonymisées :
- L’individualisation : il ne doit pas être possible d’isoler un individu dans le jeu de données. Exemple : une base de données de CV où seuls les nom et prénoms d’une personne auront été remplacés par un numéro (qui ne correspond qu’à elle) permet d’individualiser cette personne. Dans ce cas, cette base de données est considérée comme pseudonymisée et non comme anonymisée.
- La corrélation : il ne doit pas être possible de relier entre eux des ensembles de données distincts concernant un même individu. Exemple : une base de données cartographique renseignant les adresses de domiciles de particuliers ne peut être considérée comme anonyme si d’autres bases de données, existantes par ailleurs, contiennent ces mêmes adresses avec d’autres données permettant d’identifier les individus.
- L’inférence : il ne doit pas être possible de déduire, de façon quasi certaine, de nouvelles informations sur un individu.Exemple : si un jeu de données supposément anonyme contient des informations sur le montant des impôts de personnes ayant répondu à un questionnaire, que tous les hommes ayant entre 20 et 25 ans qui ont répondu sont non imposables, il sera possible de déduire, si on sait que M. X, homme âgé de 24 ans, a répondu au questionnaire, que ce dernier est non imposable.
CONCLUSION
L’anonymisation des données est une méthode créée dans le but d’exploiter des données personnelles dans le respect des droits et libertés de chacun. Plusieurs modèles existent afin de parvenir à rendre impossible l’identification des personnes. Ces données pourront ensuite être transférées en vue de créer de l’open data.
Pour en savoir plus sur ce qu’est l’open data et comment s’en servir, retrouvez notre article à venir sur notre blog : Qu’est ce que l’Open Data ?